c语言变量和数据类型
GCC
Linux下使用最广泛的C/C++编译器是GCC,大多数的Linux发行版本都默认安装,不管是开发人员还是初学者,一般都将GCC作为Linux下首选的编译工具。
保存文件后退出,打开终端并 cd 到当前目录,输入下面的命令:
gcc test.c -o test
可以看到在当前目录下多出一个文件 test,这就是可执行文件。不像Windows,Linux不以文件后缀来区分可执行文件,Linux下的可执行文件后缀理论上是可以任意更改的。
当然,也可以分步编译:
1) 预处理
gcc -E test.c -o test.i
在当前目录下会多出一个预处理结果文件 test.i,打开 test.i 可以看到,在 test.c 的基础上把stdio.h和stdlib.h的内容插进去了。
2) 编译为汇编代码
gcc -S test.i -o test.s
其中-S参数是在编译完成后退出,-o为指定文件名。
3) 汇编为目标文件
gcc -c test.s -o test.o
.o就是目标文件。目标文件与可执行文件类似,都是机器能够识别的可执行代码,但是由于还没有链接,结构会稍有不同。
3) 链接并生成可执行文件
gcc test.o -o test
如果有多个源文件,可以这样来编译:
gcc -c test1.c -o test1.o
gcc -c test2.c -o test2.o
gcc test1.o test2.o -o test
注意:如果不指定文件名,GCC会生成名为a.out的文件,.out文件只是为了区分编译后的文件,Linux下并没有标准的可执行文件后缀名,一般可执行文件都没有后缀名。
编译后生成的test文件就是程序了,运行它:
./test
如果没有运行权限,可以使用sudo命令来增加权限(注意要在Linux的分区下):
sudo cdmod test 777
对于程序的检错,我们可以用-pedantic、-Wall、-Werror选项:
-pedantic选项能够帮助程序员发现一些不符合 ANSI/ISO C标准的代码(并不是全部);
-Wall可以让gcc显示警告信息;
-Werror可以让gcc在编译中遇到错误时停止继续。
这3个选项都是非常有用的。
c语言转义字符
通过puts可以输出字符串,例如:
puts("123abc");
“123abc” 对应的ASCII码值的八进制分别是 61、62、63、141、142、143,上面的代码也可以写为:
puts("\61\62\63\141\142\143");
在C语言中,所有的ASCII码都可以用反斜杠\加数字(默认是8进制)来表示,称为转义字符(Escape Character),因为\后面的字符都不是它原来的ASCII字符的意思了。
除了八进制,也可以用十六进制来表示。用十六进制表示时数字要以x开头。”123abc” 对应的ASCII码值的十六进制分别是 31、32、33、61、62、63,所以也可以写为:
puts("\x31\x32\x33\x61\x62\x63");
注意:只能使用八进制或十六进制,不能使用十进制。
一个完整的例子:1
2
3
4
5
int main(){
puts("The string is: \61\62\63\x61\x62\x63");
return 0;
}
运行结果:
The string is: 123abc
在ASCII码中,从 0~31(十进制)的字符为控制字符,它们都是看不见的字符,不能在显示器上显示,也没法书写,只能以转义字符的形式来表示。不过,直接使用ASCII码值记忆不方便,针对常用的控制字符,C语言又定义了简写方式,完整的列表如下:
转义字符 意义 ASCII码值(十进制)
\a 响铃(BEL) 007
\b 退格(BS) ,将当前位置移到前一列 008
\f 换页(FF),将当前位置移到下页开头 012
\n 换行(LF) ,将当前位置移到下一行开头 010
\r 回车(CR) ,将当前位置移到本行开头 013
\t 水平制表(HT) (跳到下一个TAB位置) 009
\v 垂直制表(VT) 011
转义字符示例:1
2
3
4
5
int main(){
puts("C\tC++\tJava\nC first appeared!\a");
return 0;
}
运行结果:
C C++ Java
C first appeared!
同时会听到喇叭发出“嘟”的声音,这是使用\a的效果。
C语言中的空白符
空格、制表符、换行符统称为空白符,它们只能占位,没有实际的内容。
制表符也称缩进,就是Tab键,默认占用4个空格的位置,你也可以在编辑器中修改。
对于编译器,有的空白符会被忽略,有的却不能。请看下面几种 puts 的写法:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
int main()
{
puts("C语言");
puts("中文网");
puts
("C语言中文网");
puts
(
"C语言中文网"
)
;
puts ("C语言中文网");
puts ( "C语言中文网" ) ;
return 0;
}
运行结果:
C语言
中文网
C语言中文网
C语言中文网
C语言中文网
C语言中文网
看到输出结果,说明代码没有错误,以上几种 puts 的用法是正确的。puts和()之间、” “和()之间可以有任意的空白符,它们会被编译器忽略,编译器不认为它们是代码的一部分,它们的存在只是在编辑器中呈现一定的格式,让程序员阅读方便。
需要注意的是:字符串中的空格和制表符不会被忽略,它们会被输出到控制台上。并且字符串中不能有换行符,否则会产生编译错误。请看下面的代码:1
2
3
4
5
6
7
8
int main()
{
puts("C语 言 中文网");
puts("C语言
中文网");
return 0;
}
第5~6行代码是错误的,字符串必须在一行内结束,不能换行。把这两行代码删除,运行结果为:
C语 言 中文网
程序员要善于利用空白符:缩进(制表符)和换行可以让代码结构更加清晰,空格可以让代码看起来不那么拥挤。专业的程序员同样追求专业的代码格式,大家在以后的学习中可以慢慢体会。
数据类型
顾名思义,数据类型用来说明数据的类型,确定了数据的解释方式,让计算机和程序员不会产生歧义。在C语言中,有多种数据类型,例如:
说 明 字符型 短整型 整型 长整型 单精度浮点型 双精度浮点型 无类型
数据类型 char short int long float double void
这些是最基本的数据类型,是C语言自带的,如果我们需要,还可以通过它们组成更加复杂的数据类型,后面我们会一一讲解。
数据的长度(Length)
所谓数据长度(Length),是指数据占用多少个字节。占用的字节越多,能存储的数据就越多,对于数字来说,值就会更大,反之能存储的数据就有限。
多个数据在内存中是连续存储的,彼此之间没有明显的界限,如果不明确指明数据的长度,计算机就不知道何时存取结束。例如我们保存了一个整数 1000,它占用4个字节的内存,而读取时却认为它占用3个字节或5个字节,这显然是不正确的。
所以,在定义变量时还要指明数据的长度。而这恰恰是数据类型的另外一个作用。数据类型除了指明数据的解释方式,还指明了数据的长度。因为在C语言中,每一种数据类型所占用的字节数都是固定的,知道了数据类型,也就知道了数据的长度。
在32位环境中,各种数据类型的长度一般如下:
说 明 字符型 短整型 整型 长整型 单精度浮点型 双精度浮点型
数据类型 char short int long float double
长 度 1 2 4 4 4 8
C语言有多少种数据类型,每种数据类型长度是多少、该如何使用,这是每一位C程序员都必须要掌握的,后续我们会一一讲解。
总结
数据是放在内存中的,在内存中存取数据要明确三件事情:数据存储在哪里、数据的长度以及数据的处理方式。
变量名不仅仅是为数据起了一个好记的名字,还告诉我们数据存储在哪里,使用数据时,只要提供变量名即可;而数据类型则指明了数据的长度和处理方式。所以诸如int n;、char c;、float money;这样的形式就确定了数据在内存中的所有要素。
C语言提供的多种数据类型让程序更加灵活和高效,同时也增加了学习成本。而有些编程语言,例如PHP、JavaScript等,在定义变量时不需要指明数据类型,编译器会根据赋值情况自动推演出数据类型,更加智能。
除了C语言,Java、C++、C#等在定义变量时也必须指明数据类型,这样的编程语言称为强类型语言。而PHP、JavaScript等在定义变量时不必指明数据类型,编译系统会自动推演,这样的编程语言称为弱类型语言。
强类型语言一旦确定了数据类型,就不能再赋给其他类型的数据,除非对数据类型进行转换。弱类型语言没有这种限制,一个变量,可以先赋给一个整数,然后再赋给一个字符串。
最后需要说明的是:数据类型只在定义变量时指明,而且必须指明;使用变量时无需再指明,因为此时的数据类型已经确定了。
在屏幕上输出各种数据类型
在《C语言在屏幕上显示内容》一节中,我们使用 puts 来输出字符串。puts 是 output string 的缩写,只能用来输出字符串,不能输出整数、小数、字符等,我们需要用另外一个函数,那就是 printf
printf 比 puts 更加强大,不仅可以输出字符串,还可以输出整数、小数、单个字符等;输出格式也可以自己定义,例如:
以十进制、八进制、十六进制形式输出;
要求输出的数字占 n 个字符的位置;
控制小数的位数。
printf 是 print format 的缩写,意思是“格式化打印”。这里所谓的“打印”就是在屏幕上显示内容,与“输出”的含义相同,所以我们一般称 printf 是用来格式化输出的。
先来看一个简单的例子:
printf(“C语言中文网”);
这个语句可以在屏幕上显示“C语言中文网”,与puts(“C语言中文网”);的效果类似。
输出变量 abc 的值:
int abc=999;
printf(“%d”, abc);
这里就比较有趣了。先来看%d,d 是 decimal 的缩写,意思是十进制数,%d 表示以十进制的形式输出。输出什么呢?输出变量 abc 的值。%d 与 abc 是对应的,也就是说,会用 abc 的值来替换 %d。
%d 与后面的变量是一一对应的,第一个 %d 对应第一个变量,第二个 %d 对应第二个变量……
%d称为格式控制符,它指明了以何种形式输出数据。格式控制符均以%开头,后跟其他字符。%d 表示以十进制形式输出一个整数。除了 %d,printf 支持更多的格式控制,例如:
%c:输出一个字符。c 是 character 的简写。
%s:输出一个字符串。s 是 string 的简写。
%f:输出一个小数。f 是 float 的简写。
除了这些,printf 支持更加复杂和优美的输出格式,考虑到读者的基础暂时不够,我们将在《printf的高级用法》一节中展开讲解。
我们把代码补充完整,体验一下:1
2
3
4
5
6
7
8
9
int main()
{
int n = 100;
char c = '@'; //字符用单引号包围,字符串用双引号包围
float money = 93.96;
printf("n=%d, c=%c, money=%f\n", n, c, money);
return 0;
}
输出结果:
n=100, c=@, money=93.959999
要点提示:
1) \n表示换行,在《C语言转义字符》一节中有具体讲解。puts 输出完成后会自动换行,而 printf 不会,要自己添加换行符。
2) //后面的为注释。注释用来说明代码是什么意思,让我们阅读更加方便,它也是代码的一部分。编译器会忽略注释内容。
C语言中的整数(short,int,long)
整数是编程中常用的一种数据,C语言中有三种整数类型,分别为 short、int 和 long。int 称为整型,short 称为短整型,long 称为长整型,它们的长度(所占字节数)关系为:
short <= int <= long
它们具体占用几个字节C语言并没有规定,C语言只做了宽泛的限制:
short 至少占用2个字节。
int 建议为一个机器字长。32位环境下机器字长为4字节,64位环境下机器字长为8字节。
short 的长度不能大于 int,long 的长度不能小于 int。
这就意味着,short 并不一定真的”短“,long 也并不一定真的”长“,它们有可能和 int 占用相同的字节数。决定整数长度的因素很多,包括硬件(CPU和数据总线)、操作系统、编译器等。
在16位环境下,short 为2个字节,int 为2个字节,long 为4个字节。16位环境多用于单片机和低级嵌入式系统,在PC和服务器上基本都看不到了。
对于32位的 Windows、Linux 和 OS X,short 为2个字节,int 为4个字节,long 也为4个字节。PC和服务器上的32位系统占有率也在慢慢下降,嵌入式系统使用32位越来越多。
在64位环境下,不同的操作系统会有不同的结果,如下所示(长度以字节计):
操作系统 short int long
Win64 2 4 4
类Unix系统(包括 Unix、Linux、OS X、BSD、Solaris 等) 2 4 8
目前我们使用较多的PC系统为 Win XP、Win 7、Win 8、Win 10、Mac OS X、Linux,short 和 int 的长度都是固定的,分别为2和4,大家可以放心使用,long 的长度在 Win64 和类Unix系统下会有所不同,使用时要注意移植性
获取某个数据类型的长度可以使用 sizeof 操作符,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
short a = 10;
int b = 100;
long c = 1000;
char d = 'X';
int a_length = sizeof a;
int b_length = sizeof(int);
printf("a=%d, b=%d, c=%d, d=%d\n", a_length, b_length, sizeof(c), sizeof(char));
return 0;
}
在Win7下的运行结果为:
a=2, b=4, c=4, d=1
sizeof 用来获取某个数据类型或变量所占用的字节数,如果后面跟的是变量名称,那么可以省略 ( ),如果跟的是数据类型,就必须带上 ( )。
需要注意的是,sizeof 是C语言中的操作符,不是函数,所以可以不带 ( ),后面会详细讲解。
符号位
在数学中,数字有正负之分。在C语言中也是一样,short、int、long 都可以带上符号,例如:
short a = -10; //负数
int b = +10; //正数
long c = (-9) + (+12); //负数和正数相加
如果不带正负号,默认就是正数。
符号也要在内存中体现出来。符号只有正负两种情况,用1位就足以表示,这1位就是最高位。以 int 为例,它占用32位的内存,0~30位表示数值,31 位表示正负号。如下图所示:
在编程语言中,计数往往是从0开始,例如字符串 “abc123”,我们称第 0 个字符是 a,第 1 个字符是 b,第 5 个字符是 3。这和我们平时从 1 开始计数的习惯不一样,大家要慢慢适应,培养编程思维。
在符号位中,用0表示正数,用1表示负数。例如 short 类型的 -10、+16 在内存中的表示如下:
如果不希望设置符号位,可以在数据类型前面加 unsigned,如下所示:1
2
3unsigned short a = 12;
unsigned int b = 1002;
unsigned long c = 9892320;
这样,short、int、long 中就没有符号位了,所有的位都用来表示数值。也就意味着,使用了 unsigned 只能表示正数,不能表示负数了。
如果是unsigned int,那么可以省略 int ,只写 unsigned,例如:1
unsigned n = 100;
它等价于:1
unsigned int n = 100;
输出无符号数使用%u,代码如下
如果是unsigned int,那么可以省略 int ,只写 unsigned,例如:1
unsigned n = 100;
它等价于:1
unsigned int n = 100;
输出无符号数使用%u,代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#include <stdio.h>
#include <stdlib.h>
int main()
{
int a=1234;
unsigned a1=1234;
int b=0x7fffffff;
int c=0x80000000; // 0x80000000 = 0x7fffffff + 0x1
int d=0xffffffff;
unsigned e=0xffffffff;
printf("a=%d, a(u)=%u\n", a, a);
printf("a1=%d, a1(u)=%u\n", a1, a1);
printf("b=%d, b(u)=%u\n", b, b);
printf("c=%d, c(u)=%u\n", c, c);
printf("d=%d, d(u)=%u\n", d, d);
printf("e=%d, e(u)=%u\n", e, e);
system("pause");
return 0;
}
输出结果:
a=1234, a(u)=1234
a1=1234, a1(u)=1234
b=2147483647, b(u)=2147483647
c=-2147483648, c(u)=2147483648
d=-1, d(u)=4294967295
e=-1, e(u)=4294967295
可以发现,无论变量声明为有符号数还是无符号数,只有当以 %u 格式输出时,才会作为无符号数处理;如果声明为 unsigned,却以 d% 输出,那么也是有符号数。
d、e 的输出值之所以为 -1,与它们在内存中的存储形式有关,我们将在《C语言整数在内存中的存储》一节中详细介绍
取值范围和数据溢出
short、int、long 占用的字节数不同,所能表示的数值范围也不同。以32位平台为例,下面是它们的取值范围:
数据类型 所占字节数 取值范围
short 2 -32768~32767,即 -215~(215-1)
unsigned short 2 0~65535,即 0~(216-1)
int 4 -2147483648~2147483647,即 -231~(231-1)
unsigned int 4 0~4294967295,即0~(232-1)
long 4 -2147483648~2147483647,即 -231~(231-1)
unsigned long 4 0~4294967295,即0~(232-1)
1 |
|
运行结果:
a=0
变量 a 为 int 类型,占用4个字节(32位),能表示的最大值为 0xFFFFFFFF,而 0x100000000 = 0xFFFFFFFF + 1,占用33位,已超出 a 所能表示的最大值,会发生溢出,最高位被截去,剩下的32位都是0。也就是说,在 a 被输出前,其值已经变成了 0
整数的前缀
在程序中是根据前缀来区分十进制、八进制和十六机制的。
1) 十进制数由 0~9 十个数字组成,没有前缀。例如:
合法的十进制数:237、-568、65535、1627;
不合法的十进制数:023(不能有前导0)、23D(含有非十进制数码)。
2) 八进制数由 0~7 八个数字组成,必须以0开头,即以0作为八进制数的前缀。例如:
合法的八进制数:015(十进制为13)、-0101(十进制为-65)、0177777(十进制为65535);
不合法的八进制数:256(无前缀0)、03A2(包含了非八进制数码)。
注意前缀是数字0,而不是字母o。
3) 十六进制数由数字0~9、字母A~F或a~f组成,前缀为0X或0x。例如:
合法的十六进制数:0X2A(十进制为42)、-0XA0(十进制为-160)、0xffff(十进制为65535);
不合法的十六进制数:5A(无前缀0X)、0X3H(含有非十六进制数码)。
在C语言中不能直接表示二进制,它没有特定的前缀
整数的后缀
1) 可以用后缀L或l来表示长整型数。例如:
十进制长整型数:158L、358000L;
八进制长整型数:012L、077L、0200000L;
十六进制长整型数:0X15L (十进制为21)、0XA5L、0X10000L。
长整型数158L和基本整型数158 在数值上并无区别,但由于 158L 是长整型数,编译器将为它分配 sizeof(long) 字节的存储空间。
2) 可以用后缀U或u来表示无符号数,例如 358u、0x38Au等。
前缀、后缀可以同时使用以表示各种类型的整数。例如 0XA5Lu 表示十六进制无符号长整型数 A5,其十进制为165。
实际开发中经常使用前缀,但较少使用后缀,因为将整数赋值给变量时就确定了它是否为 long 类型、是否为 unsigned 类型。
各种整数的输出
在使用 printf 输出整数时,不同的控制字符会有不同的输出格式。
1) 输出 int 使用%d,输出 short 使用 %hd,输出 long 使用 %ld。
使用 %d 输出 short,或使用 %ld 输出 int、short 时由于不会发生溢出,所以能够正确输出。而使用 %d 输出 long、或使用 %hd 输出 int、long 时可能会发生数据溢出,导致输出错误。请看下面的例子:1
2
3
4
5
6
7
8
9
10
11
int main()
{
unsigned short a = 100, b = 0x10000;
long c = 0x10, d = 0x10000;
printf("a=%d, b=%d\n", a, b);
printf("c=%hd, d=%hd\n", c, d);
system("pause");
return 0;
}
运行结果:
a=100, b=0
c=16, d=0
变量a、b为 unsigned short 类型,占用2个字节,能表示的最大值为 0XFFFF。a 在输出时使用 %d,能容纳的数值比 a 大,自然不会发生溢出。而 b 被赋值 0x10000,0x10000>0xFFFF,在赋值时就已经发生了溢出,其值为 0,所以 %d 也输出 0。
变量 c、d 为 long 类型,占用4个字节,能表示的最大值为 0XFFFFFFFF,它们在赋值时都没有溢出。当以 %hd 输出时,会截去较高的两个字节,只输出较低两个字节中的内容。c 的值为 0x10,存储在较低的两个字节中,所以 %hd 能够正确输出。而 d 的值为 0x10000,较低的两个字节全部为0,输出时它的值也就为 0。
实际开发中使用 %d 和 %ld 足以,几乎不使用 %hd。
2) 输出无符号数使用%u。上面已经讲过,不再赘述。
3) 输出十进制使用%d,输出八进制使用%o,输出十六进制使用%x或%X。如果希望带上前缀,可以加#,例如 %#d、%#o、%#x、%#X。请看下面的例子:1
2
3
4
5
6
7
8
9
10
11#include <stdio.h>
#include <stdlib.h>
int main()
{
int a = 100, b = 0270, c = 0X2F;
printf("a(d)=%d, d(#d)=%#d\n", a, a);
printf("a(o)=%o, d(#o)=%#o\n", b, b);
printf("c(x)=%x, c(#x)=%#x, c(X)=%X, c(#X)=%#X\n", c, c, c, c);
system("pause");
return 0;
}
运行结果:
a(d)=100, d(#d)=100
a(o)=270, d(#o)=0270
c(x)=2f, c(#x)=0x2f, c(X)=2F, c(#X)=0X2F
需要说明的是:
- 十进制数没有前缀,所以 %d 和 %#d 的输出结果一样。
- %o、%x、%X 都是以无符号形式输出。
C语言中的浮点数(float,double)
小数也称实数或浮点数。例如,0.0、75.0、4.023、0.27、-937.198 都是合法的小数。这是常见的小数的表现形式,称为十进制形式。
除了十进制形式,也可以采用指数形式,例如 7.25×102、0.0368×105、100.22×10-2 等。任何小数都可以用指数形式来表示
在C语言中小数的指数形式为:
aEn 或 aen
a 为尾数部分,是一个十进制数,n 为指数部分,是一个十进制整数,E或e是固定的字符,其值为 a×10n。例如:
- 2.1E5 = 2.1×105,其中2.1是尾数,5是指数。
- 3.7E-2 = 3.7×10-2,其中3.7是尾数,-2 是指数。
- 0.5E7 = 0.5×107,其中0.5是尾数,7是指数。
C语言中小数的数据类型为 float 或 double:float 称为单精度浮点数,double 称为双精度浮点数。不像整数,小数的长度始终是固定的,float 占用4个字节,double 占用8个字节。
10 是固定的,不需要在内存中体现出来。正负号、指数(n)、尾数(a) 是变化的,需要占用内存空间来表示。
float、double 在内存中的形式如下所示:
输出 float 使用 %f 控制符,输出 double 使用 %lf 控制符,如下所示:1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
float a=128.101;
float b=0.302f;
float c=1.23002398f;
double d=123;
double e = 78.429;
printf("a=%f \nb=%f \nc=%f \nd=%lf \ne=%lf\n", a, b, c, d, e);
system("pause");
return 0;
}
运行结果:
a=128.100998
b=0.302000
c=1.230024
d=123.000000
e=78.429000
对代码的说明:
1) %f 默认保留六位小数,不足六位以 0 补齐,超过六位按四舍五入截断。
2) 将整数赋值给 float 变量时会转换为小数。
3) 小数默认为 double 类型,加上后缀f才是float类型。
4) 由于内存有限,小数的精度受限,所以输出 a 时只能获得一个近似数。这点我们将在《C语言float、double的内存表示》中重点讲解。
C语言中的字符(char)
我们在《C语言在屏幕上显示内容》和《C语言转义字符》中提到了字符串,它是多个字符的集合,例如 “abc123”、”123\141\142\143”;当然也可以只包含一个字符,例如 “a”、”1”、”\63”。
不过为了使用方便,我们可以用 char 类型来专门表示一个字符,例如:1
2
3
4
5char a='1';
char b='$';
char c='X';
char d=' '; // 空格也是一个字符
char e='\63'; //也可以使用转义字符的形式
char 称为字符类型,只能用单引号’ ‘来包围,不能用双引号” “包围。而字符串只能用双引号” “包围,不能用单引号’ ‘包围。
输出字符使用 %c,输出字符串使用 %s。
在《C语言转义字符》中讲到的转义字符是一种特殊字符,读者可以结合本节再回忆一下。
字符与整数
先看下面一段代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
#include <stdlib.h>
int main()
{
char a = 'E';
char b = 70;
int c = 71;
int d = 'H';
printf("a=%c, a=%d\n", a, a);
printf("b=%c, b=%d\n", b, b);
printf("c=%c, c=%d\n", c, c);
printf("d=%c, d=%d\n", d, d);
system("pause");
return 0;
}
输出结果:
a=E, a=69
b=F, b=70
c=G, c=71
d=H, d=72
在ASCII码表中,E、F、G、H 的值分别是 69、70、71、72。
字符和整数没有本质的区别。可以给 char 变量一个字符,也可以给它一个整数;反过来,可以给 int 变量一个整数,也可以给它一个字符。
char 变量在内存中存储的是字符对应的 ASCII 码值。如果以 %c 输出,会根据 ASCII 码表转换成对应的字符;如果以 %d 输出,那么还是整数。
int 变量在内存中存储的是整数本身,当以 %c 输出时,也会根据 ASCII 码表转换成对应的字符。
也就是说,ASCII 码表将整数和字符关联起来了。不明白的读者请重温《ASCII编码与Unicode编码》一文,并猛击这里查看整数与字符的完整对应关系。
字符串
C语言中没有字符串类型,只能使用间接的方法来表示。可以借助下面的形式将字符串赋值给变量:1
char *variableName = "string";
char和*是固定的形式,variableNmae 为变量名称,”string” 是要赋值的字符串。
由于大家的基础还不够,这里暂时不深入探讨,大家暂时记住即可,我们会在《C语言指针》一节中详细介绍。
字符串使用示例:1
2
3
4
5
6
7
8
9
10
11
12
13
int main()
{
char c = '@';
char *str = "This is a string.";
printf("char: %c\n", c);
printf("string1: %s\n", str);
//也可以直接输出字符串
printf("string2: %s\n", "This is another string.");
system("pause");
return 0;
}
运行结果:
char: @
string1: This is a string.
string2: This is another string.
C语言标识符、关键字和注释
标识符
定义变量时,我们使用了诸如“a”“abc”“mn123”这样的名字,它们都是程序员自己起的,一般能够表达出变量的作用,这叫做标识符(Identifier)。
标识符就是程序员自己起的名字,除了变量名,后面还会讲到函数名、宏名、结构体名等。不过,名字也不能随便起,
C语言规定,标识符只能由字母(A~Z, a~z)、数字(0~9)和下划线(_)组成,并且第一个字符必须是字母或下划线。
以下标识符是合法的:
a, x, x3, BOOK_1, sum5
以下标识符是非法的:
3s 不能以数字开头
sT 出现非法字符
-3x 不能以减号(-)开头
bowy-1 出现非法字符减号(-)
在使用标识符时还必须注意以下几点:
- C语言虽然不限制标识符的长度,但是它受到不同编译器的限制,同时也受到具体机器的限制。例如在某个编译器中规定标识符前128位有效,当两个标识符前128位相同时,则被认为是同一个标识符。
- 在标识符中,大小写是有区别的,例如BOOK和book 是两个不同的标识符。
- 标识符虽然可由程序员随意定义,但标识符是用于标识某个量的符号,因此,命名应尽量有相应的意义,以便于阅读理解,作到“顾名思义”。
关键字
关键字(Keywords)是由C语言规定的具有特定意义的字符串,通常也称为保留字,例如 int、char、long、float、unsigned 等。我们定义的标识符不能与关键字相同,否则会出现错误。
你也可以将关键字理解为具有特殊含义的标识符,它们已经被系统使用,我们不能再使用了。
标准C语言中一共规定了32个关键字,大家可以参考C语言关键字及其解释[共32个],后续我们会一一讲解
注释
注释(Comments)可以出现在代码中的任何位置,用来向用户提示或解释程度的意义。程序编译时,会忽略注释,不做任何处理,就好像它不存在一样。
C语言支持单行注释和多行注释:
单行注释以//开头,直到本行末尾(不能换行);
多行注释以/开头,以/结尾,注释内容可以有一行或多行。
一个使用注释的例子:1
2
3
4
5
6
7
8
9
10
11
12
13/*
Powered by: c.biancheng.net
Author: xiao p
Date: 2015-6-26
*/
int main()
{
/* puts 会在末尾自动添加换行符 */
puts("http://c.biancheng.net");
printf("C语言中文网\n"); //printf要手动添加换行符
return 0;
}
运行结果:
http://c.biancheng.net
C语言中文网
在调试程序的过程中可以将暂时不使用的语句注释掉,使编译器跳过不作处理,待调试结束后再去掉注释。
需要注意的是,多行注释 不能嵌套使用。例如下面的注释是错误的:
/*C语言/*中文*/网*/
而下面的注释是正确的:
/*C语言中文网*/ /*c.biancheng.net*/
C语言加减乘除运算
C语言也可以进行加减乘除运算,但是运算符号与数学中的略有不同,见下表。
加法 减法 乘法 除法 求余数
数学 + - × ÷ 无
C语言 + - * / %
加号、减号与数学中的一样,乘号、除号不同,另外C语言还多了一个求余数的运算符。
我们先来看一段代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
int a=12;
int b=100;
float c=8.5;
int m=a+b;
float n=b*c;
double p=a/c;
int q=b%a;
printf("m=%d, n=%f, p=%lf, q=%d\n", m, n, p, q);
system("pause");
return 0;
}
输出结果:
m=112, n=850.000000, p=1.411765, q=4
你也可以让数字直接参与运算:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
int main()
{
int a=12;
int b=100;
float c=8.9;
int m=a-b; // 变量参与运算
int n=a+239; // 有变量也有数字
double p=12.7*34.3; // 数字直接参与运算
printf("m=%d, n=%d, p=%lf\n", m, n, p);
printf("m*2=%d, 6/3=%d, m*n=%ld\n", m*2, 6/3, m*n);
system("pause");
return 0;
}
输出结果:
m=-88, n=251, p=435.610000
m2=-176, 6/3=2, mn=-22088
对于除法,需要注意的是除数不能为 0,所以诸如int a=3/0;这样的语句是错误的。
加减乘除的简写
先来看一个例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
int main()
{
int a=12;
int b=10;
printf("a=%d\n", a);
a=a+8;
printf("a=%d\n", a);
a=a*b;
printf("a=%d\n", a);
system("pause");
return 0;
}
输出结果:
a=12
a=20
a=200
第一次输出 a 原来的值;a=a+8;相当于用a+8的值替换原来 a 的值,所以第二次输出 20;第三次用a*b的值替换第二次的值,所以是 200。
在C语言中,表达式a=a#b可以简写为a#=b,#表示 +、-、*、/、% 中的任何一种运算符。
上例中a=a+8;可以简写为a+=8;,a=ab;可以简写为a=b;。
下面的简写形式也是正确的:
复制纯文本新窗口
int a = 10, b = 20;
a += 10; //相当于 a = a + 10;
a = (b-10); //相当于 a = a (b-10);
a -= (a+20); //相当于 a = a - (a+20);
注意:a#=b 仅是一种简写,不会影响效率。
C语言自增(++)和自减(–)
一个整数自身加一可以这样写:1
a+=1;
它等价于a=a+1;。
但是在C语言中还有一种更简单的写法,就是a++;或者++a;。这种写法叫做自加或自增;意思很明确,就是自身加一。
相应的,也有a–和–a,叫做自减,表示自身减一。
++和–分别称为自增和自减运算符。
自增和自减的示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
#include <stdlib.h>
int main()
{
int a = 10, b = 20;
printf("a=%d, b=%d\n", a, b);
++a;
--b;
printf("a=%d, b=%d\n", a, b);
a++;
b--;
printf("a=%d, b=%d\n", a, b);
system("pause");
return 0;
}
运行结果:
a=10, b=20
a=11, b=19
a=12, b=18
自增自减完成后,会用新值替换旧值,并将新值保存在当前变量中。自增自减只能针对变量,不能针对数字,例如10++是错误的。
值得注意的是,++ 在变量前面和后面是有区别的:
++ 在前面叫做前自增(例如 ++a)。前自增先进行自增操作,再进行其他操作。
++ 在后面叫做后自增(例如 a++)。后自增先进行其他操作,再进行自增操作。
自减(–)也一样,有前自减和后自减之分。
请看下面的例子:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#include <stdio.h>
#include <stdlib.h>
int main()
{
int a=10, a1=++a;
int b=20, b1=b++;
int c=30, c1=--c;
int d=40, d1=d--;
printf("a=%d, a1=%d\n", a, a1);
printf("b=%d, b1=%d\n", b, b1);
printf("c=%d, c1=%d\n", c, c1);
printf("d=%d, d1=%d\n", d, d1);
system("pause");
return 0;
}
输出结果:
a=11, a1=11
b=21, b1=20
c=29, c1=29
d=39, d1=40
a、b、c、d 的输出结果相信大家没有疑问,下面重点分析a1、b1、c1、d1:
1) 对于a1=++a,先执行++a,结果为11,再将11赋值给a1,所以a1的最终值为11。而a经过自增,最终的值也为11。
2) 对于b1=b++,b的值并不会立马加1,而是先把b原来的值交给b1,然后再加1。b原来的值为20,所以b1的值也就为20。而b经过自增,最终值为21。
3) 对于c1=–c,先执行–c,结果为29,再将29赋值给c1,所以c1的最终值为29。而c经过自减,最终的值也为29。
4) 对于d1=d–,d的值并不会立马减1,而是先把d原来的值交给d1,然后再减1。d原来的值为40,所以d1的值也就为40。而d经过自减,最终值为39。
可以看出:a1=++a;会先进行自增操作,再进行赋值操作;而b1=b++;会先进行赋值操作,再进行自增操作。c1=–c;和d1=d–;也是如此。
自增自减非常方便,后续编程中会经常用到,大家要注意区分。
为了强化记忆,我们再来看一个自增自减的综合示例:1
2
3
4
5
6
7
8
9
10
11
12
int main()
{
int a=12;
int b=1;
int c=a-(b--); // ①
int d=(++a)-(--b); // ②
printf("c=%d, d=%d\n", c, d);
system("pause");
return 0;
}
输出结果:
c=11, d=14
我们来分析一下:
1) 执行语句①时,会先进行a-b运算,结果是11,然后 b 再自减,就变成了 0,最后再将a-b的结果(也就是11)交给 c,所以 c 的值是 11。
2) 执行语句②之前,b 的值已经变成 0。对于d=(++a)-(–b),a 会先自增,变成 13,然后 b 再自减,变成 -1,最后再进行13-(-1),结果是14,交给 d,所以 d 最终是 14。
C语言运算符的优先级和结合性
先来看一个例子:1
2
3
4
5
6
7
8
int main(){
int a=10,b=1,c=2;
a=b=c;
printf( "12+3*5=%d\n", 12+3*5);
printf( "a=%d, c=%d\n", a, c);
return 0;
}
运行结果:
12+3*5=27
a=2, c=2
1) 对于表达式12+35,很明显先进行乘法运算,计算35,结果为15,再进行加法运算,计算12+15,结果为27。也就是说,乘法的优先级比加法高,要先计算,这与数学中的规则是一样的。
所谓优先级,就是当有多个运算符在同一个表达式中出现时,先执行哪个运算符。如果不想按照默认的规则执行,可以加( ),例如(12+3)5的结果为 75,(2+5)(10-4)的结果为 42。大部分情况下,它们的规则和数学中是相同的。
2) 对于语句赋值语句a=b=c;,先执行b=c,再执行a=b,而不是反过来,这说明赋值操作符=具有右结合性。
所谓结合性,就是当一个运算符多次出现时,先执行哪个运算符。先执行右边的叫右结合性,先执行左边的叫左结合性。
表达式(Expression)和语句(Statement)的概念在C语言中并没有明确的定义:
表达式可以看做一个计算的公式,往往由数据、变量、运算符等组成,例如3*4+5、a=c=d等,它的结果必定是一个值;
语句的范围更加广泛,不一定是计算,不一定有值,可以是某个操作、某个函数、选择结构、循环等。
值得注意的是:以分号;结束的往往称为语句,而不是表达式,例如34+5;、a=c=d;等。
3) 像 +、-、、/ 这样的运算符,它的两边都有数据,例如 3+4、a*3 等,有两个操作数,我们称这样的运算符为双目运算符。后面还会讲解单目运算符和三目运算符。
C语言中有几十种运算符,这里不一一说明,大家可以点击《C语言运算符的优先级和结合性一览表》查看完整列表
C语言的运算符众多,具有不同的优先级和结合性,我们将它们全部列了出来,方便大家对比和记忆:

注:同一优先级的运算符,运算次序由结合方向所决定。
上面的表无需死记硬背,很多运算符的规则和数学中是相同的,用得多,看得多自然就记得了。如果你是在记不住,可以使用( )。
一些容易出错的优先级问题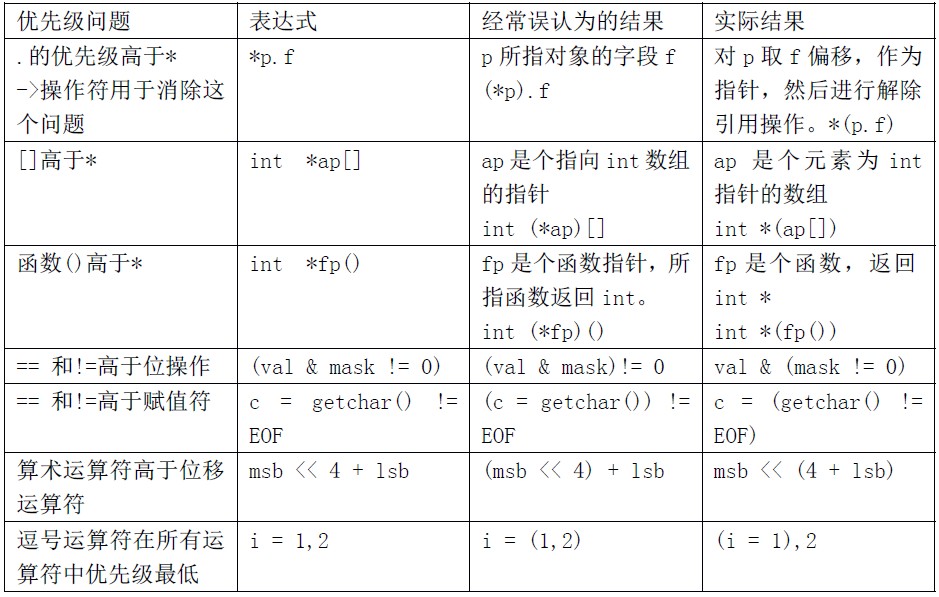
上表中,优先级同为1 的几种运算符如果同时出现,那怎么确定表达式的优先级呢?这是很多初学者迷糊的地方。下表就整理了这些容易出错的情况:
这些容易出错的情况,希望读者好好在编译器上调试调试,这样印象会深一些。一定要多调试,光靠看代码,水平是很难提上来的。调试代码才是最长水平的。
C语言数据类型转换
数据类型转换就是将数据(变量、表达式的结果)从一种类型转换到另一种类型。例如,为了保存小数你可以将int类型的变量转换为double类型。
数据类型转换的一般格式为:
(type_name) expression
type_name为要转换到的数据类型,expression为表达式。例如:1
2
3(float) a; //把a转换为实型
(int)(x+y); //把x+y的结果转换为整型
(float) 100; //将一个常量转换为实型
【示例】将整数转换为浮点数:1
2
3
4
5
6
7
8
int main(){
int sum = 17, count = 5;
double mean;
mean = (double) sum / count;
printf("Value of mean : %f\n", mean);
return 0;
}
运行结果:
Value of mean : 3.400000
需要注意的是,类型转换运算符( )的优先级高于/,(double) sum / count会先将 sum 转换为 double 类型,然后再进行除法运算。如果写作(double) (sum / count),那么运行结果就是 3.000000。
这种由程序员显式进行的转换称为强制类型转换。除了强制类型转换,在不同数据类型的混合运算中编译器也会隐式地进行数据类型转换,称为自动类型转换。
自动类型转换遵循下面的规则:
- 若参与运算的数据类型不同,则先转换成同一类型,然后进行运算。
- 转换按数据长度增加的方向进行,以保证精度不降低。例如int型和long型运算时,先把int量转成long型后再进行运算。
- 所有的浮点运算都是以双精度进行的,即使仅含float单精度量运算的表达式,也要先转换成double型,再作运算。
- char型和short型参与运算时,必须先转换成int型。
- 在赋值运算中,赋值号两边的数据类型不同时,需要把右边表达式的类型将转换为左边变量的类型。如果右边表达式的数据类型长度比左边长时,将丢失一部分数据,这样会降低精度。
下图表示了类型自动转换的规则:![]()
【示例】自动数据类型转换。1
2
3
4
5
6
7
8
9
10#include<stdio.h>
int main(){
float PI=3.14159;
int s1, r=5;
double s2;
s1 = r*r*PI;
s2 = r*r*PI;
printf("s1=%d, s2=%f\n", s1, s2);
return 0;
}
运行结果:
s1=78, s2=78.539753
在计算表达式r*r*PI时,r 和 PI 都转换成double类型,表达式的结果也为double类型。但由于 s1 为整型,所以赋值运算的结果仍为整型,舍去了小数部分。
注意是将小数部分直接丢掉,而不是按照四舍五入向前舍入。
无论是强制转换或是自动转换,都只是为了本次运算的需要而对变量的数据长度进行的临时性转换,而不改变数据说明时对该变量定义的类型。请看下面的例子:1
2
3
4
5
6
int main(){
float f=5.75;
printf("(int)f=%d, f=%f\n",(int)f, f);
return 0;
}
运行结果:
(int)f=5, f=5.750000